
Give Your Business Users A Friendly Interface To Your Data Platform
Written by: Kris Peeters
Modern data platforms are complex. If you look at reference architectures, like the one from A16Z below, it contains 30+ boxes. Each box can be one or more tools, depending on how you design it. You might not need all boxes in your specific data platform, most data platforms we see in the real world often contain 10+ tools.
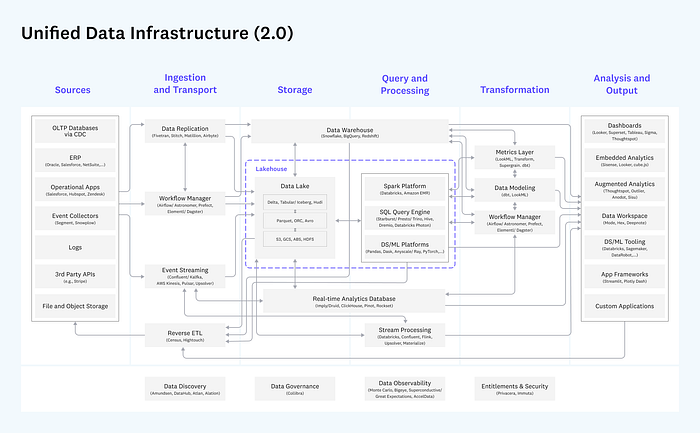 https://a16z.com/emerging-architectures-for-modern-data-infrastructure/
https://a16z.com/emerging-architectures-for-modern-data-infrastructure/
Building a data platform for a small team is NOT the hard part
While this might seem intimidating, the data world is pretty comfortable with building data platforms like these. If you go to a cloud vendor, you get many of these tools out of the box and you really require nothing more than a simple terraform script to configure. Or, if you really want to keep it simple, click it together in their console. Think of combining a few AWS services with Snowflake, or setting up Databricks on Azure, or even running an old-fashioned Cloudera Hadoop cluster on-prem. Today, setting up a data platform that can handle a few use cases, which are built by a centralised data team, is a matter of days, weeks, or at most a few months.
Bag of tools vs an integrated experience
But, you only end up with a bag of tools. This brings a few challenges:
- You didn’t take away any cognitive load: Each developer needs to understand each of the tools in your data platform and needs to combine them in a way that works for their particular use case.
- No interfaces: It’s hard to change or upgrade a tool. Each use case is a collection of scripts that trigger the underlying tools. Changing or upgrading tools means breaking all your use cases.
- It’s hard to see the big picture: Something breaks in a dashboard? That’s because some random notebook, 5 steps upstream, contained a bug. You need to check your CICD system to know what was the last deployment made for that notebook and then you open github to inspect the actual change.
Again, this is fine if you build a few use cases with a small central data team. You can train each person and give each use case special love and care.
But what if you want to decentralise the teams?
Data mesh, data fabric, citizen data science, self-service BI, … You can call it any hype word you like, there is a clear trend of giving everyone in the business the capability to do something with data. And there is an obvious reason for that: because business users needs to and wants to use data to make their lives easier.
Let me repeat that for people in the back: Business users both need and want to use data to make their lives easier. Don’t believe me? Walk into any business unit of your company and observe the crazy complex things they do with Excel and Access. Check the super advanced data pipelines they build in their dashboarding tool. See how some of their analysts spend 7 days each month manually consolidating numbers from different systems and putting the results in a powerpoint.
We did a project at a large company which still had one monolithic data warehouse. And a single team was responsible for building all use cases. This would take anywhere between 6 months and 2 years, and they had a backlog of 9 months. So a business unit wanted something? Come back in 2 years and it will be shipped, maybe. We built a self-service data platform for them, and within 3 months, we onboarded 100+ use cases from 200+ business users who would connect to the data using MS Access. “Oh no the horror”? No, that’s awesome. At least we know who’s using which datasets for which purposes. Are there better tools out there than Access? Yes. Will their business logic be a complete mess? Yes. Is that our first priority? No. The business logic is something they own.
My point is: You want those users on your platform to remove the central bottleneck, and once these users are onboarded on the platform, you cannot just give them a bag of tools anymore.
Obligatory car analogy
No engineering blog is complete without a car analogy. In the book Platform Strategy by Gregor Hohpe, he makes the case that the auto industry has moved on from the “Bag of Tools” approach a long time ago. If a manufacturer wants to release a new model (== build a new use case), they don’t go to a long shelve of tools, like the A16Z diagram above. They don’t pick a piston, a steering wheel, a radiator, … and start combining all of that for their particular model.
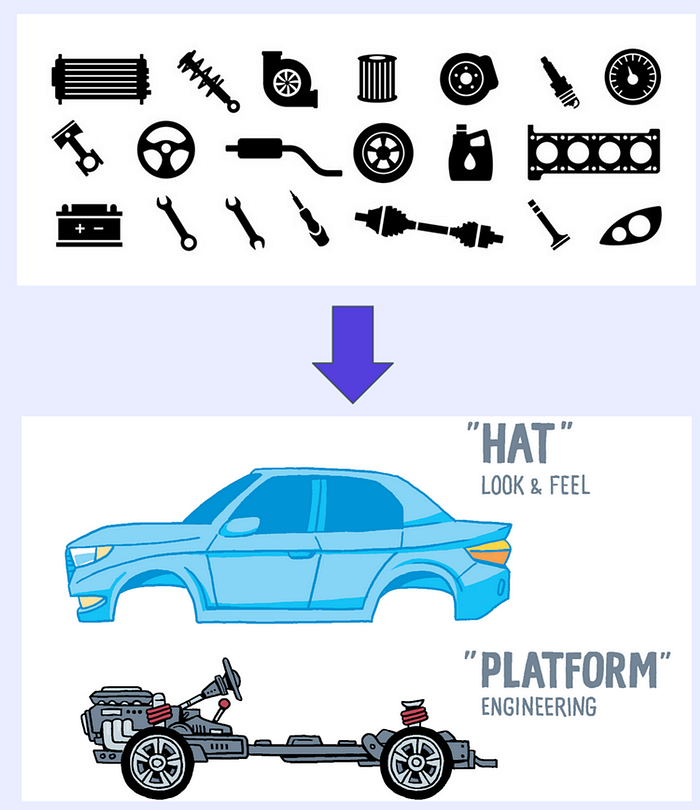 Top image by author. Bottom image from Platform Strategy by Gregor Hohpe
Top image by author. Bottom image from Platform Strategy by Gregor Hohpe
Instead, they build a platform once, and allow multiple models to be built on top of that. This brings several benefits vs the bag of tools approach:
- Reduced cognitive load: All engineering aspects of driving a car are abstracted away. The platform team can focus on performance, durability and cost-effectiveness of the platform. The model team can focus on customer experience.
- Clean interface for the model builders: They just have to make sure the driver can use the steering wheel and the pedals. They don’t need to know how the brakes and suspension are integrated with the wheels. That can change over time, without effecting the interface to the model builders.
- Easy to see the big picture: As part of the interface, the platform builders display the status on the dashboard: “Needs oil change”, “liquid fluid almost empty”, … For more advanced status messages, experts can connect to the CAN-bus of the car.
Now back to data platforms
Data platform teams should provide the same approach to data platforms. Instead of just offering a bag of tools to their use case teams, they should think about the capabilities they want to offer to use case teams and which interfaces they need to make that happen.
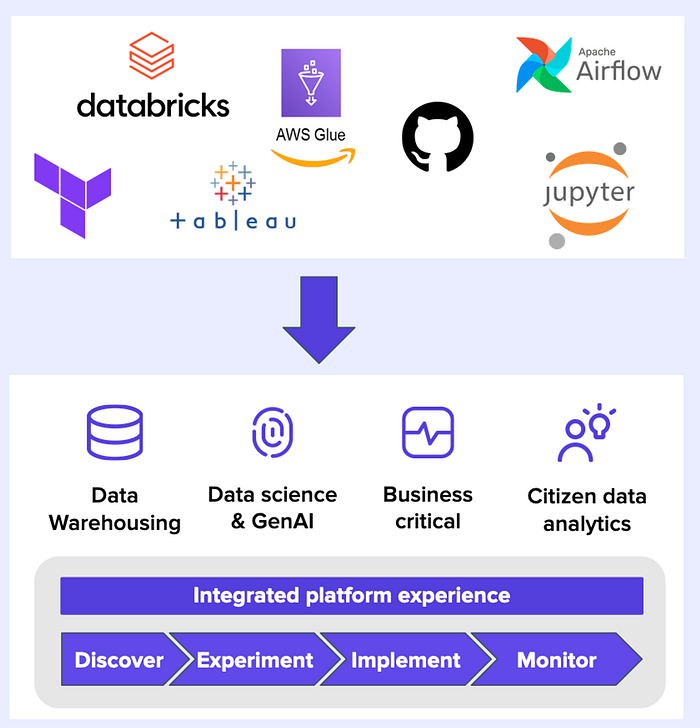 Image by author
Image by author
This interface can be different from company to company. And it also depends at which maturity level you are with the platform. But broadly speaking, there are 4 archetypes of use cases that you can build on a data platform:
- Data warehousing: Integrate data sources, track historical changes, build reports
- Data science & GenAI: Use data to make predictions, serve recommendations or give advice
- Business-critical use cases: Run at high SLA, integrated with business processes
- Citizen Data analytics: Often called “last-mile analytics”: enable the business user to do some simple transformations and build dashboards
Each of these use case prototypes go through the same 4 phases: Discover, Experiment, Implement, Monitor. And maybe even “sunset”. Companies have different names for these phases and sometimes they make them more granular. The Discover phase can be about making a business case, aligning with company strategy, identifying the data sources you need, getting budget approvals, …
Use case teams understand these concepts. They don’t necessarily understand the words “Airflow DAG” or “Iceberg Table” or “pip install”. It’s your job to offer paved roads to these use case teams. So they can select “I want to do a new Data science use case”, and magically, behind the scenes, a git repo is created, a mlops data pipeline is built, a model repository is being added, a notebook is being created, ….
Example interface from our Data Product Portal
Last month, we have introduced our open-source project, the Data Product Portal. For teams who want to work with a Data Product approach, this is a great way of exposing a technology-independent interface to their use case teams: Use case teams can define new data products, add users to data products, link datasets to data products, … And behind the scenes, this gets translated to your specific infrastructure, whether that is Snowflake or Databricks or AWS.
Here are some screenshots of our API docs so you get a feel of what the interface is that we offer:
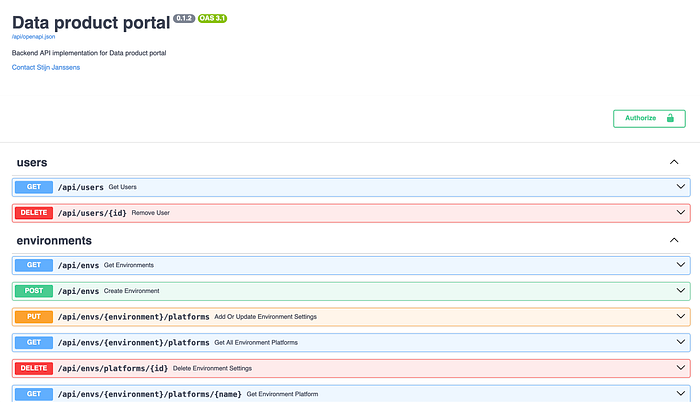 https://portal.public.demo1.conveyordata.com/api/docs#/
https://portal.public.demo1.conveyordata.com/api/docs#/
Without going into details on each endpoint, this interface allows you to build and configure data products in a technology-independent way. How that is translated to an actual toolchain, is another blog.
And of course, not every user speaks “API”. So there is also a web UI. Public demo here.
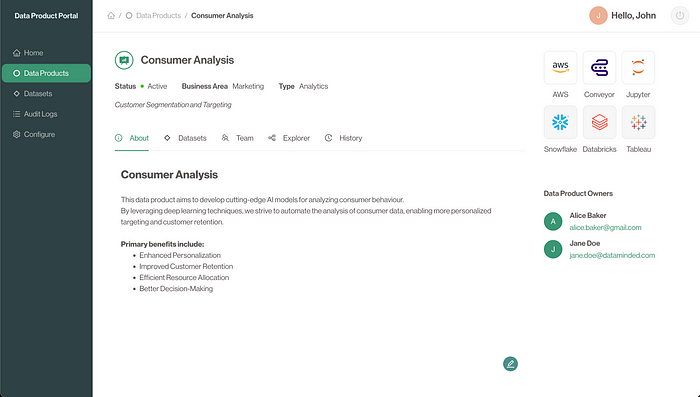 https://portal.public.demo1.conveyordata.com/data-products/ffcf5286-8f14-4411-8dfe-75dc7ed9ec36
https://portal.public.demo1.conveyordata.com/data-products/ffcf5286-8f14-4411-8dfe-75dc7ed9ec36
Conclusion
The message of this blog is that, as a platform engineer, you should do more than offer a bag of tools to your users. You should design a data platform interface that is technology-independent and that suits the particular needs of your company.
If you are adopting Data Product thinking, check out the Data Product Portal which is available as an open source project on Github. If you have questions or want to share your thoughts? Join our project community on Slack and connect with us directly.

