
How Portal Integrates With Data Platforms
A couple of weeks ago we officially announced the release of as an open source repository. The Data Product Portal is an open-source tool to help organisations build and manage data products at scale. It’s intuitive, flexible, and geared towards making data product management straightforward and effective.
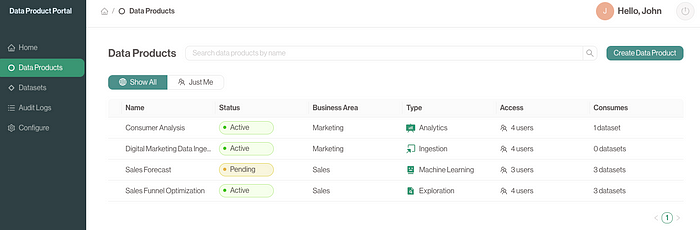 Data product portal frontend example
Data product portal frontend example
It aims to integrate all data product aspects related to data governance, data platforms and user management into a single solution.
We often get asked questions on how the data product portal interacts with data platforms and tooling.
The aim of this blogpost is to explain exactly that. It addresses questions like: how will the data product portal interact with my data platform, how are data products defined, how can people interact with data products and their data access scope, how does this translate to data platform resources ie. storage buckets, databases and tooling for building data products.
The example in this blogpost is based upon AWS. In upcoming releases of the data product portal we intend to add support for other data platforms like Databricks, Snowflake, Azure and others. We welcome and encourage you to contribute in order to accelerate the development!
Data product portal concepts
In the announcement blogpost we described a Data Product as:
An initiative with a clear goal, owned by a department or domain that consists of: access to data, tooling and artefacts where team members work together on. Data product outputs can be shared for consumption with other data products.
These data products concepts can be visualised as follows:
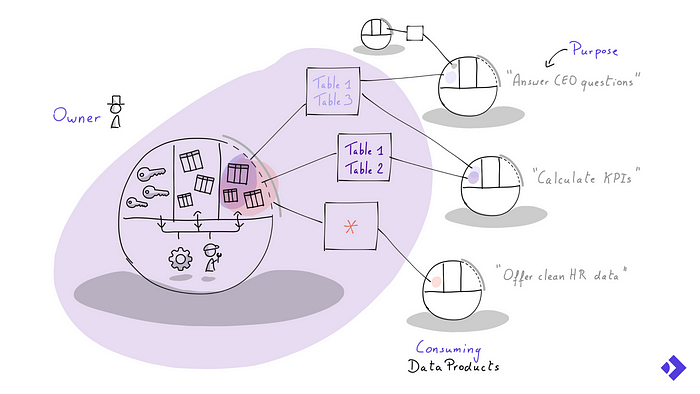 How data products interact with each other
How data products interact with each other
One of the important consequences is that access to data is organised at the data product level and not at the person level. This means that the scoped data access permissions and other governance rules are shared between the processing, tooling and people in scope of that data product.
The difficulty that comes with a data product thinking approach is coming up with a practical implementation that combines these concepts together. How to set up a data product scope for your data platform, the data governance requirements and the people that need to interact with the data product is a hard problem to solve.
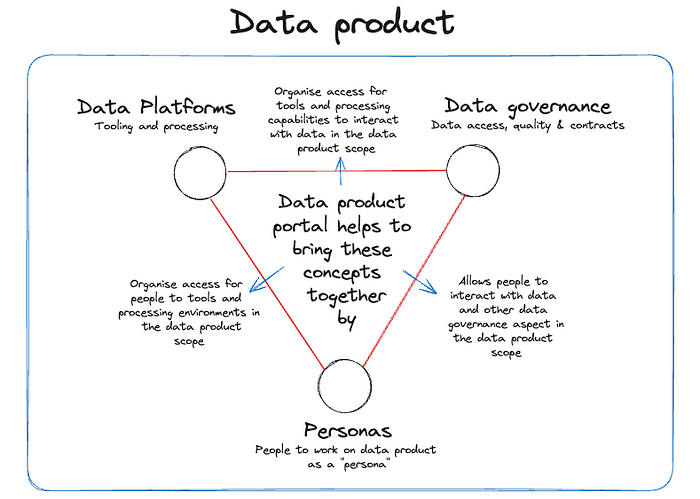 How portal aims to bring data platforms, governance and people together in a single concept
How portal aims to bring data platforms, governance and people together in a single concept
Integration concepts
This is where the Data Product Portal comes in. It is a process tool that provides clear and simple concepts that are translated into a practical implementation. This helps both technical people working on data products and people from business departments to keep control and provide insights about how their data is being used in an organisation.
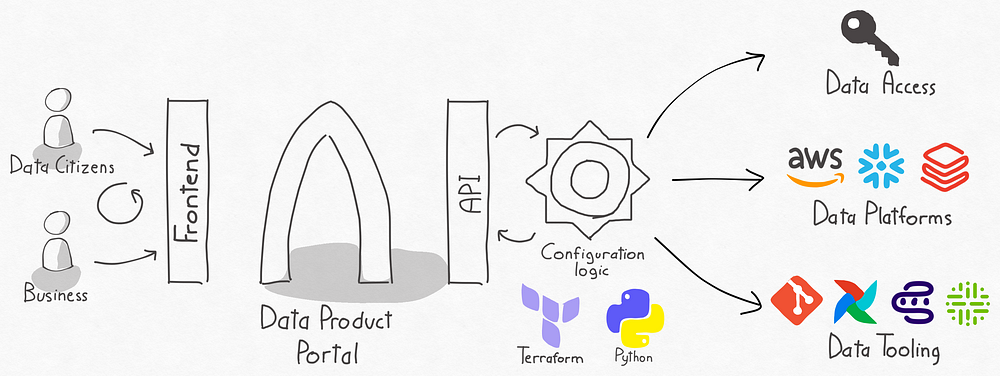 High level integration concept
High level integration concept
In the above diagram, people working with data and business users interact with the data product portal through our frontend process to configure their data products and organise access to data produced by other data products. This configuration is stored and managed in the data product portal backend. Data platform configuration logic can interact with the data product portal API’s to retrieve that configuration. This logic will translate that configuration into a practical implementation of how to:
- Configure access to data: Create data access permissions per data product and allow people, data platforms and tools to interact with that data in the scope of the data product: i.e. AWS IAM, Databricks Unity grants, Snowflake permissions
- Configure data platforms: Configuring data platforms properly to be able to build data products and allow people to do so in the scope of a data product that has the correct data access permissions: i.e. AWS Glue/Batch/Athena, Databricks workspaces, Snowflake DWH’s.
- Configure tooling: People working with data have to interact with a lot of tools to be able to build/run and operate data products. Portal makes sure that those tools are properly configured and integrated for your users in a data product scope: i.e. Github as code repository, Airflow for scheduling, as a data product workflow management, Collibra as a data catalog.
Data platform teams can write their own configuration logic based on these concepts, but they can also use the default configuration logic provided by the data product portal written in terraform. With the default configuration logic, we offer integrations with AWS and out of the box, but we intend to extend these integrations to Databricks, Azure, Snowflake, Tableau, Collibra and other relevant tools.
Integration steps
If you want to use the default AWS integration using terraform provided with the data product portal, you can do so by performing the following steps:
More on this is available on our open source git repository
Configure terraform setup
- Set AWS credentials: These AWS credentials will be used to define your data platform environments (S3 buckets, glue databases, IAM roles, Athena workgroups,…) and in what account these resources will be created in.
- Set up terraform state file: This is a technical prerequisite for being able to run terraform, there are a lot of good resources online available on how to set this up properly. An example state file can be found here.
- Configure your data platform: In our terraform code base we allow the user to configure some aspects of the data platform that are currently not managed by the data product portal. Things like VPC, DNS, infrastructure components (i.e. kubernetes for portal installation) and data environments (i.e. creation of secure S3 buckets) should be configured there.
- Choose the modules relevant to you: If you already have a networking setup and don’t need any infrastructure components beside the data environment S3 buckets and data product specific IAM roles, you can disable the modules you don’t need. At minimum you need the environment and data_products modules enables to end up with a working data platform.
Run terraform code with sample configuration files
Our terraform code base also contains a sample configuration that defines 2 data products, 3 datasets and 3 data outputs and their relationships. I suggest to start with this configuration during the AWS integration via terraform. If you have correctly set up your terraform configuration you should be able to set up your data environments and data product IAM permissions based on your configuration.
 terraform path and commands to execute
terraform path and commands to execute
Retrieve configuration directly from the portal backend
Once you have your terraform setup and data product portal correctly up and running, you can start integrating these components together. Stijn Janssens wrote a blogpost on how you can install the data product portal using docker compose or via a helm chart on your Kubernetes cluster.
It is possible in the data product portal to define an API key that can be used to retrieve information directly from our backend to replace the sample configuration. This API key can be defined in the helm chart during the Kubernetes installation process and can be used to directly interact with our backend APIs.
A complete description of our API docs is available if you perform docker compose up and browse to http://localhost:8080/api/docs
 Open API spec of the data product portal
Open API spec of the data product portal
With the API key and the OpenAPI description you should be able to retrieve all relevant information from the portal and translate that to the configuration structure that the terraform code base requires. An example python script is available that will do exactly that.
Automatically run terraform changes on portal updates
Once you feel comfortable with retrieving the configuration from the portal backend and applying the infrastructure via terraform automatically you can trigger the retrieval and terraform script automatically.
As we have learned that many organisations have different procedures for running infrastructure and terraform changes, we allow for organisations to decide on what works for them the best. This approach also allows you to integrate the data product portal easily with your already existing platform code base.
Closing thoughts
Out of experience we have learned that many organisations are struggling to translate their self-service data product thinking strategy towards a practical implementation. We hope that the data product portal will give you inspiration on how to actually achieve that and would suggest that you try it out!
If you want to know more, please check out the open-source git repository or come join the conversation on our Slack channel , we'd love to talk about development directions and all things open source for data product management.

