
How To Conquer The Complexity Of The Modern Data Stack
Images like the one below, originating from graph theory, often occur in (pseudo-)scientific research about the ideal team size, as the number of communication lines are an approximation of complexity. This has led to software, and data teams, limiting the amount of people in a (scrum) team.
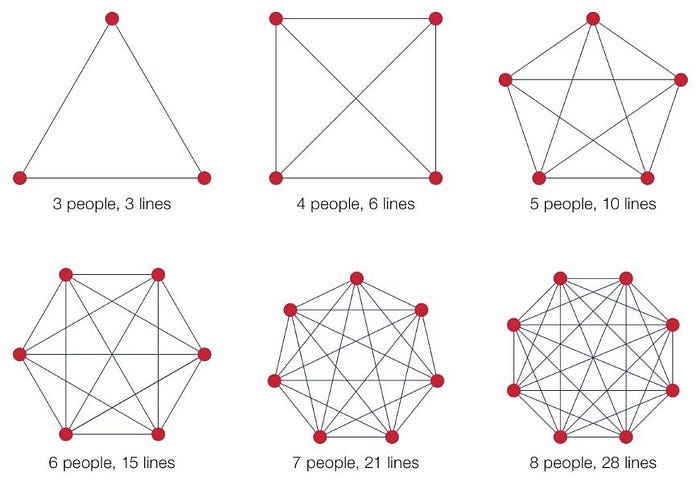 Exponentially increasing amount of edges with additional nodes in a graph
Exponentially increasing amount of edges with additional nodes in a graph
This graph theory can be used in other contexts as well. The modern data stack for example consists of a wide variety of tools, all needing to be integrated with each other, drastically increasing the complexity of your data landscape. Assuming you are able to limit your data landscape to one tool per capability, you still have a tool for ingestion, storage, compute, ETL, orchestration, visualization, advanced analytics, and data governance: 8 tools, 28 possible integrations! And then I didn’t even mention monitoring, security or deployment yet.
It can’t be this complex…
These 28 integrations sound frightening, no? Immediately you have the feeling that it can’t be this complex, and luckily it isn’t: the graph isn’t fully connected. Your visualization tool for example, does not need to be integrated with your ingestion tool. Both “communicate” through your storage layer. And there are many more integrations you can omit. Still leaving you though with an astonishing set of 8 tools and 17 integrations.
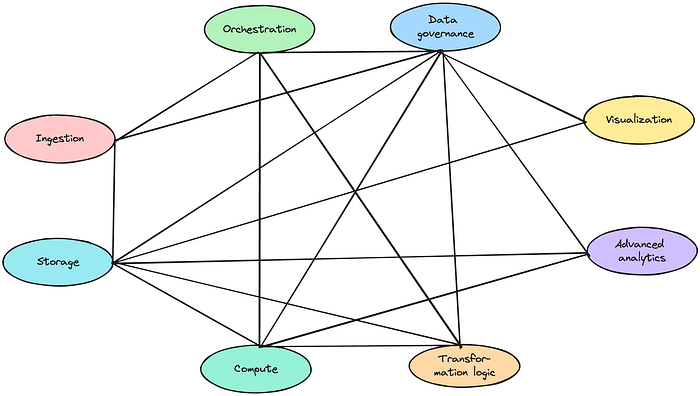 8 tools with 17 out of a maximum of 28 possible integrations — Image by Author
8 tools with 17 out of a maximum of 28 possible integrations — Image by Author
Some widely adopted tools on the market cover multiple of these capabilities. dbt for example, allows you to have compute and transformation logic in one. Snowflake on the other hand, brings you storage and compute. And Databricks would join compute and advanced analytics.
Next to that, most tools come with some governance functionality baked into them. Although it would leave you with a platform where access management and other governance capabilities, are managed locally within each tool, lacking a global overview, it would eliminate a number of integrations, as the data governance category could be replaced with a data catalog.
Assume you limit governance to a catalog and you select Snowflake, it would still leave you with the following platform consisting of 7 tools and 11 integrations.
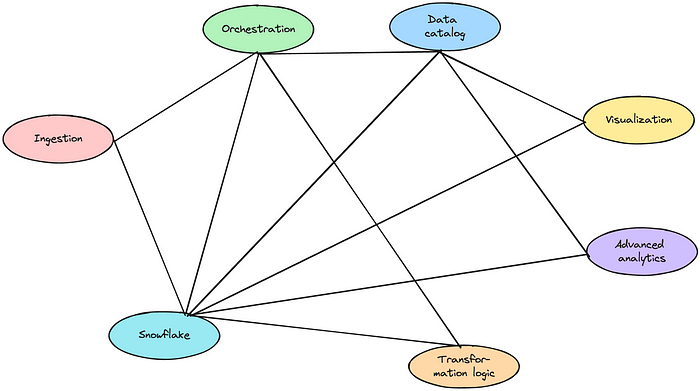 7 tools with a remainder of 11 integrations to manage — Image by Author
7 tools with a remainder of 11 integrations to manage — Image by Author
Even though we already have eliminated one tool from our modern data stack and have drastically decreased the number of integrations, this modern data stack requires some effort.
It remains obvious that maintaining and upgrading 7 tools and 11 integrations is a cumbersome and time-consuming task.
Digging deeper to unveil even more complexity
Let us stop the approximation of complexity of your data platform by measuring the number of tools and integrations for a while, and look to it from a different angle, let’s switch to data dependencies. Naming conventions aside, a typical approach used to be to store the data as is, clean it up, and make it usable.
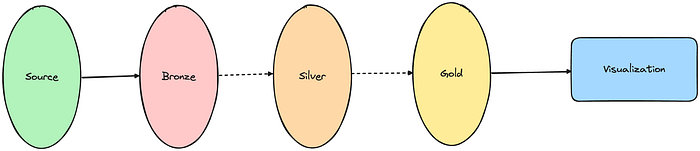 Traditional layered approach with few (2) data dependencies, managed by a single team — Image by Author
Traditional layered approach with few (2) data dependencies, managed by a single team — Image by Author
It is also noteworthy that traditionally this set-up was implemented and managed by a central data team. As we are talking people again: communication needed to be in place to discuss how to get the data from source to bronze and how to structure the data in gold. As a consequence, the central data team did need to be experts in your entire business. Let’s say this is quite unrealistic.
This has led to more and more companies introducing multiple teams to work with data, within their business context, while guaranteeing the reusability of their data. This is being referred to as introducing product thinking to data or building data products in the context of a business domain. As a downside, these companies are introducing more data handovers, or communication lines.
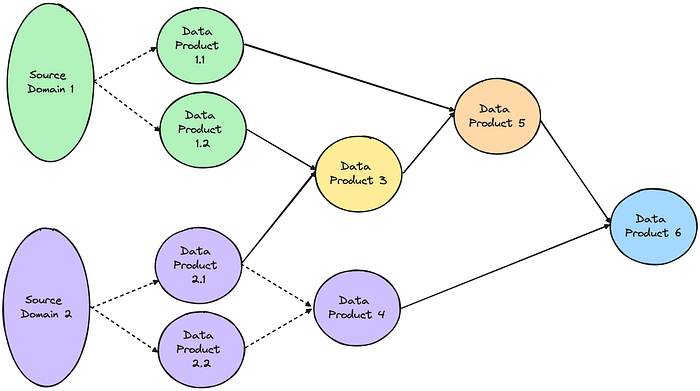 Example of how the federated product thinking approach introduces more data handovers (6) — Image by Author
Example of how the federated product thinking approach introduces more data handovers (6) — Image by Author
A side effect of allowing multiple teams to work with data is that they do not all have the same technical expertise or tooling preference. This comes with the risk of landing on a data stack with even more tools and integrations. But even when you succeed in maintaining your data landscape slender and minimizing the number of technical integrations, your number of communication lines will go up exponentially.
Do we need this complex data stack?
One could ask him or herself whether we need this complex data stack? Let’s assume you are already convinced that you do need a data stack, and that you have valuable data use-cases. This should really be the first question you ask yourself, but not the focus of this blogpost. Secondly there are two questions to be answered:
- Do I need separate tools for every capability?
- Do I need multiple teams to work with data?
Let’s start with the second question, as subquestions leading to the answer are more black-and-white. It’s all about how far you want and need to go in self-serving the data needs of people. Remember that having a single, central data team, requires them to grasp your entire business, up until the goals of every departement and technical implementation of every business domain.
When hitting a certain number of business domains, you need to bring focus to data workers, and when you bring focus by assigning them to a single business domain, you should consider organizing them close to their stakeholders. It’s a natural next step after self-service BI and I have called it the before.
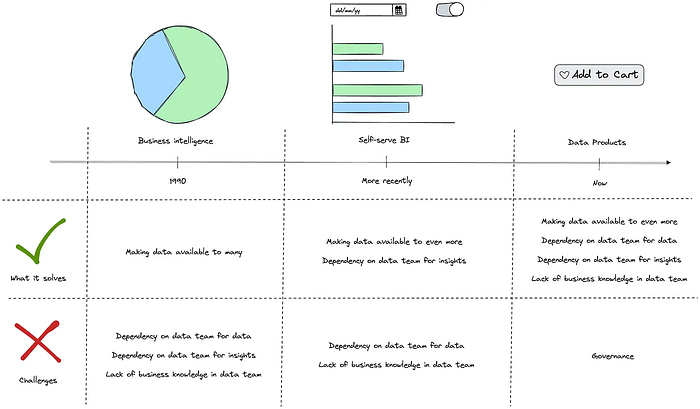 Federated data products, the third wave of data democratization — Image by Author
Federated data products, the third wave of data democratization — Image by Author
So from a given scale of business capabilities and data workers, it does make sense to move to multiple teams, but is up to you to decide what this tipping point is for you. The resulting organizational structure also impacts the answer on the first question “Do I need separate tools for every capability?”, as more people divided in multiple teams impacts the required capabilities and probably means that you have people working with different technical levels with your data stack.
The term “Modern Data Stack” was gaining traction around 2019–2020. More and more companies were creating a data landscape consisting of best-in-class tools for every capability, and did include quite a lot of open source tools and cloud vendor services. Even large vendors like Snowflake, dbt, Fivetran, and others did position themselves as part of the modern data stack.
Nowadays however, these same large vendors are adding more capabilities to their tools: think about Databricks adding unity, Snowflake buying Streamlit, Collibra introducing data shopping and data access management, …
Even though the vendor market is shifting, many organizations still prefer to use open source tools and cloud vendor services or the combination of both: many cloud vendors are offering a managed Airflow for example.
So even though the vendor space is looking for some convergence, the question remains valid, and your answer depends on technical skills, engineering culture, budget and many more.
How to make the modern data stack manageable?
Let’s assume your preference is to use best-in-class tools, rather than one application trying to solve everything. How do you make sure that this remains manageable? Let’s first establish the fact that building a data platform is hardly ever a core competence, nor a core concern, of an organization introducing one. Building the data products on top of it and delivering value from it is. This implies that you should look to managed services where possible and calculate whether the cost of the managed service is lower than the cost of managing it yourself. In most cases it does.
Next to that, there are tools on the market that offer a set of best-in-class tools, or help you manage external integrations. Think about a combination of Conveyor and Portal for example.
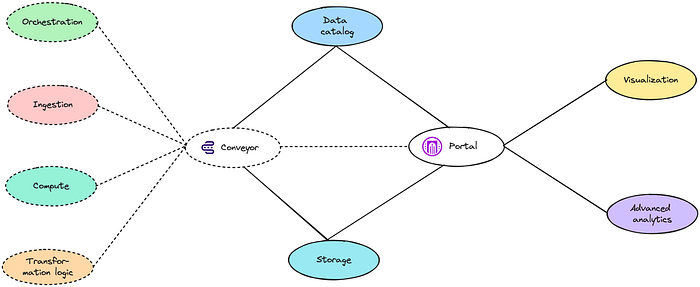 Reduced platform maintenance through the use of Conveyor and Portal — Image by Author
Reduced platform maintenance through the use of Conveyor and Portal — Image by Author
- , a data product development workbench, allows you stop worrying about orchestration, ingestion, compute and writing transformation logic, as it comes with best-in-class actors within those spaces. Additionally it covers your monitoring, security and deployment capabilities which we have omitted for now.
- , a process governance tool, puts most governance capabilities in place, allowing you to safely limit yourself to an additional data governance, while keeping the overview in place. It also drastically simplifies the onboarding of new data products, and everything you need to build them.
Even more: both Portal and Conveyor simplify the integrations with other tools like storage and data catalogs. And as a final benefit, Conveyor comes as a managed service, again reducing the amount of maintenance you have. Portal is currently only available as an open source project and has not yet a managed offering.
In the past, I personally made the estimation that maintaining all tools which Conveyor offers, integrating them, and again maintaining the integrations, was a full-time job for at least 2 of our 30 data engineers. From a cost-benefit perspective, you can make the calculations what you can spend on these tools to be profitable and switch your focus to what really matters: building the value on top of it.
Simplified communication and collaboration
Again circling back to team structures and communication lines, a set-up like the one above does not lower the number of communication lines, but simplifies them. The data product portal is the entry point for every users journey and hence the single place for communication. Even though there are quite a lot of dependencies and interactions, having such a single communication channel drastically reduces the complexity.

