
Beyond Medallion: New Data Architectures For The Age Of Data Products
For years, data platforms — particularly data lakes and lakehouses — have relied on the medallion architecture. This tiered system categorises data into three layers: bronze, silver, and gold (or raw, clean, and master, with some variations). The idea is simple: as data moves through these layers, its quality and usability increases.
In this post, we’ll explore what the medallion architecture is about, how it affects self-service data teams, and how you can organise your data to overcome the challenges of this approach with self-service in mind using our new open-source project Data Product Portal.
NEW >> Sign-up for our upcoming webinar.
The Medallion Architecture
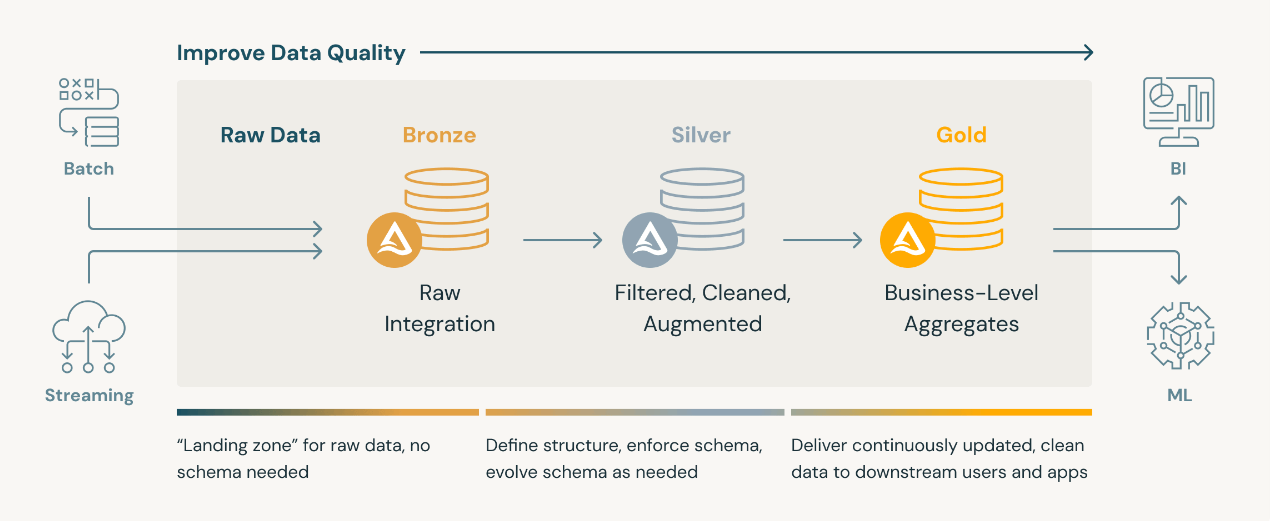 Databricks representation of the Medallion architecture
Databricks representation of the Medallion architecture
The medallion architecture organises data into three distinct tiers:
- Bronze: This is raw data, extracted directly from source systems (databases, APIs, services, etc.) without any transformation. Extraction follows common patterns like full table dumps, delta extractions (only changes between time periods), or Change Data Capture (reflecting all changes made to a data source). Data in the bronze layer is typically stored as CSV or Parquet/ORC files, organised by extraction date, along with metadata to help recreate the current state of the source data.
- Silver: This layer focusses on schema enforcement, data type corrections, and filtering out inconsistencies. Once extracted, data is transformed, reconstructed and cleaned in the silver tier. While the data is more refined, the data structure usually still mirrors the source system. This stage ensures consistent, quality data that’s ready for further use. Data engineers typically handle this process.
- Gold: This is the business-ready layer, where analysts, data scientists, and other stakeholders combine and aggregate data to create high-value datasets. These datasets power business processes such as dashboards, APIs, or machine learning models.
Medallion Architecture and Self-Service Data Teams
The medallion architecture brings some clear benefits, particularly in maintaining structure and order. Since data is organised around a tiered system, it’s relatively easy to discover data sources. However, not all data in your platform needs to made shareable i.e. experiment and intermediate processing data, also data extracted from source systems is often not in a shareable state.
Forcing all data in a similar data structure makes your data structure too rigid and is in many cases too complex. At the same time, data architects have to tightly control how and where data is stored to avoid the typical data swamp where data is spread-out, disorganised and ownership is unclear.
The Medallion Architecture was defined when central data teams were the norm and self-service data product teams were not yet considered.
The tight control data architects need to keep over the data platform structure can slow things down. Every time a team wants to create or share a new dataset, they need to involve data architects to determine where it should live.
This friction limits agility, hampers self-service capabilities and overburdens data architects with requests. This becomes even more apparent as an organisation aims to scale up their data initiatives and moves towards a self-service data platform or adopts a data product thinking approach.
Shifting towards a Data Product Thinking approach
For companies aiming to enable self-service data product teams to work on many use cases in parallel, adopting a data product thinking approach is key.
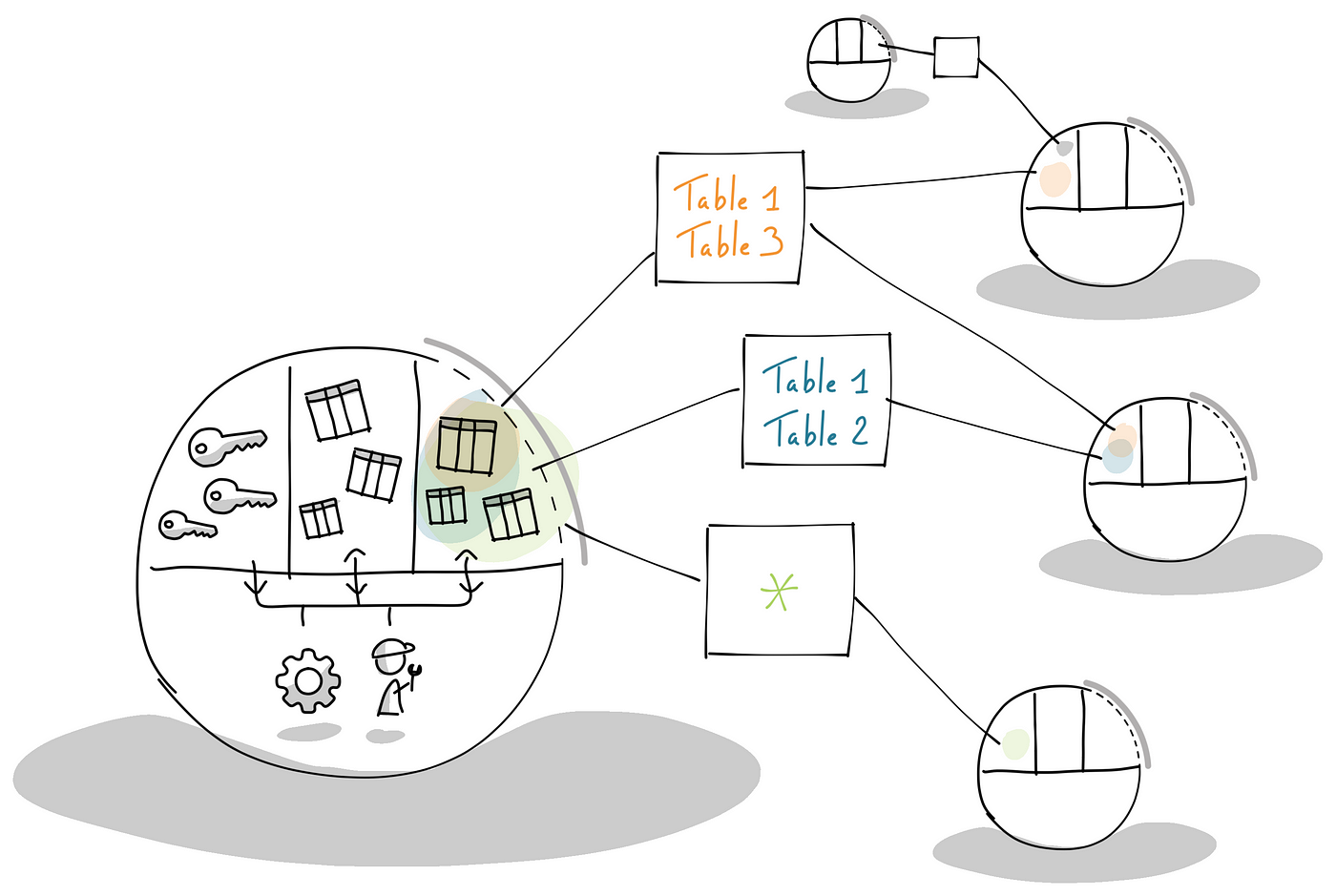 Data product thinking approach
Data product thinking approach
In this approach, teams working on a data product with a clear goal can create new data outputs, building on data produced by other teams. Each team works within the scope of their own data product, allowing for autonomy and flexibility.
Teams work in the scope of a data product with a clear goal, creating data outputs for sharing based on data from other data products.
This way of working allows organisations to scale data initiatives across multiple teams, giving more control and transparency over who is using what data, how it’s being used, and what data is being derived from it. Ultimately, data product thinking strengthens governance, making it easier for both technical and business stakeholders to track data flow and usage across the organisation.
Organising Data for Self-Service Data Product Thinking
When enabling self-service for data product teams, the traditional medallion structure doesn’t always provide the required flexibility.
When considering data products, we propose the following concepts for managing data. A data product has:
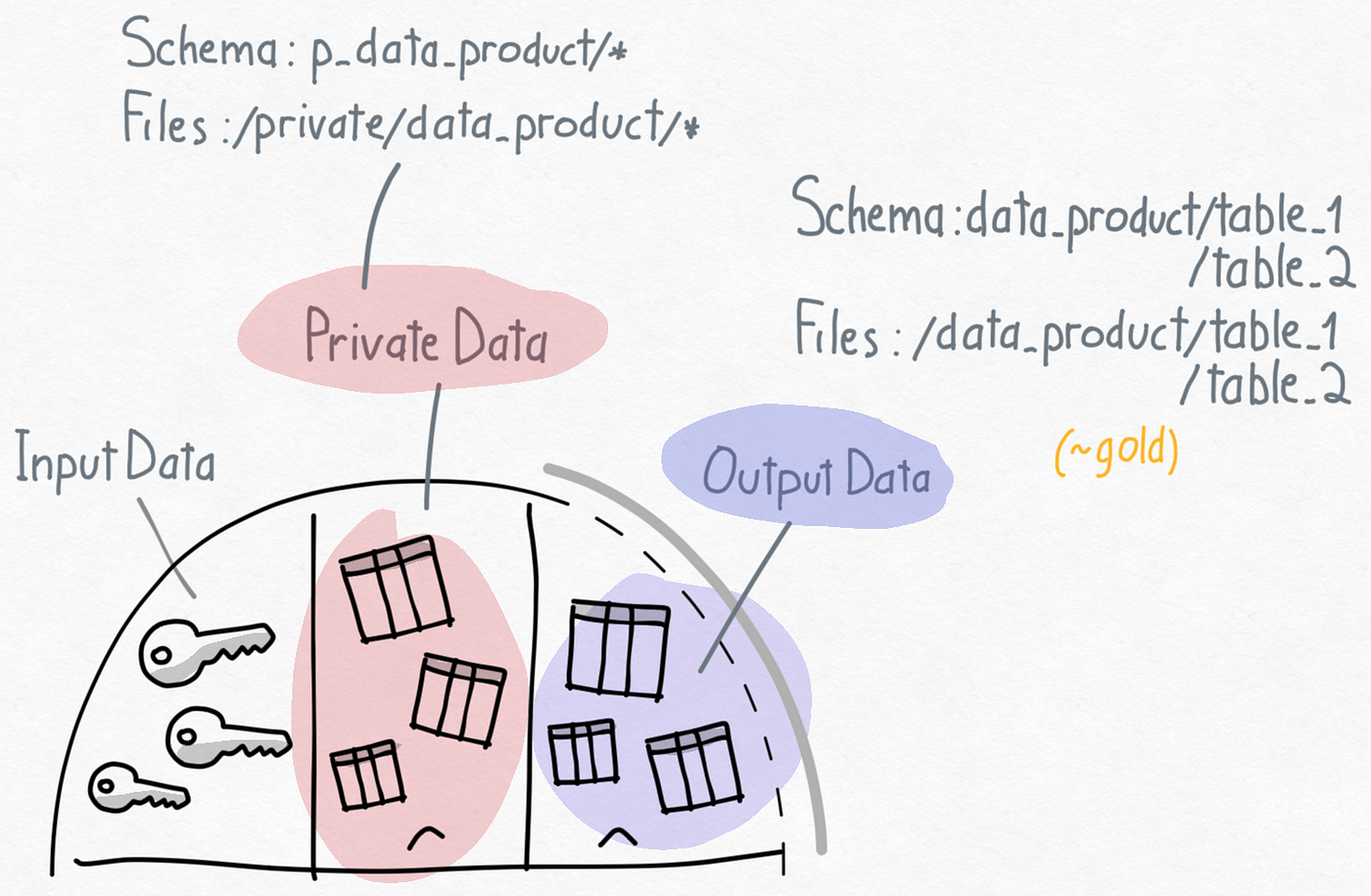
- Input data: Output data from other data products that is used as input by this data product. People working on the data product get read-only access towards input data.
- Private data: Data that is private to the data product and will never be shared outside the scope of the data product. Private data provides teams the flexibility and safety guarantees they need to work on data products. People working on the data product have full read & write permissions on private data.
- Output data: Data assets created in scope of the data product by the data product team for sharing with other data products. These data outputs need to be registered for sharing so other data products can request read access. Data products can register multiple data outputs for sharing. People working on the data product get read and write access to the output data after registration.
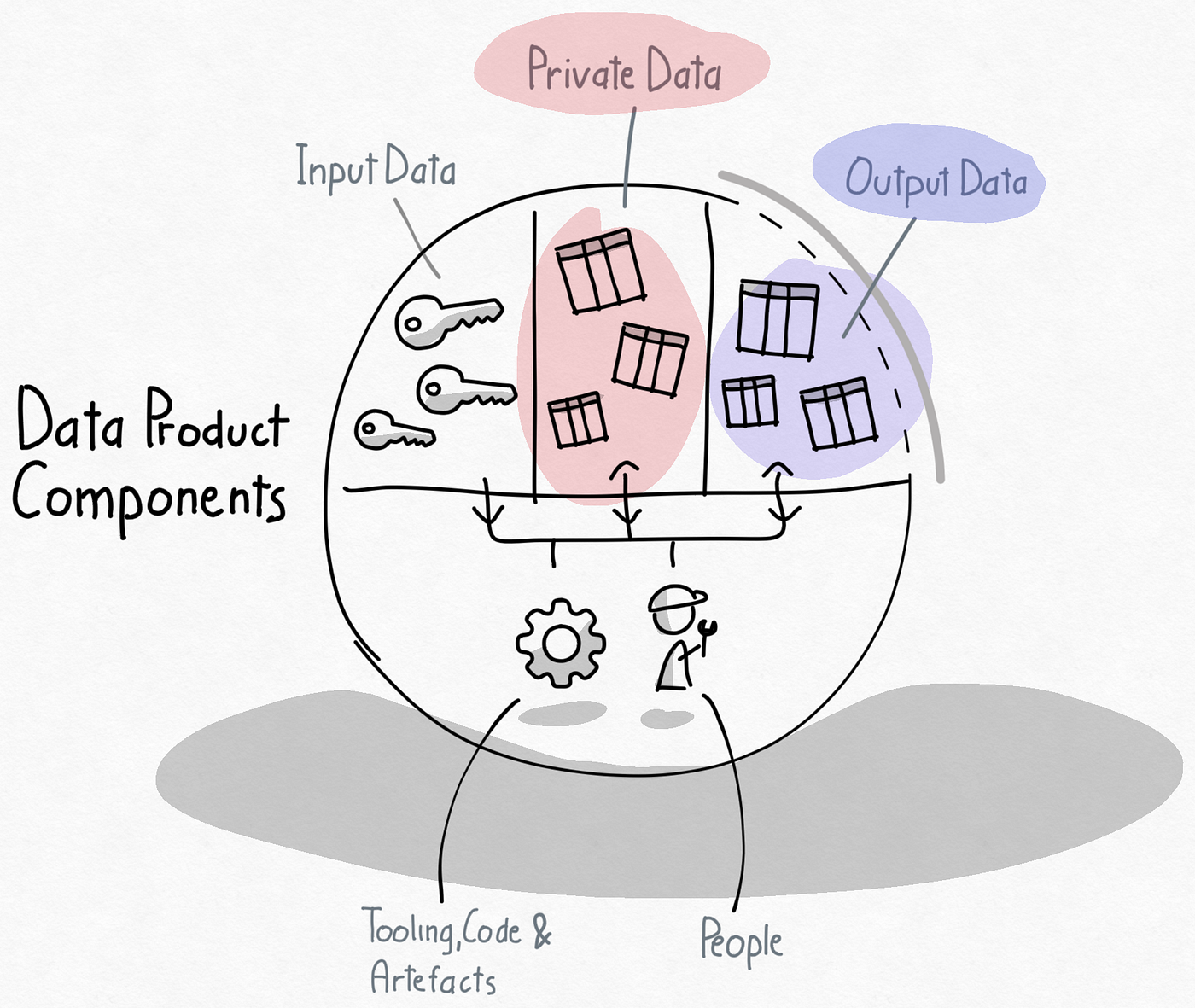 Data categories within the scope of a data product
Data categories within the scope of a data product
Data can be files stored on buckets, databases, schema’s or tables in data warehouses or lakehouses. How data is stored and registered, depends on the storage technology (i.e. AWS, Azure, Databricks, Snowflake) you are working with, but the concepts remain valid.
Depending on your needs, we propose to consider two main data organisation patterns, each with its trade-offs in terms of flexibility, governance, and control.
1. Data Product-Aligned Organisation
In this model, data is organised directly around individual data products. Teams can define a specific storage location, schema, database or table for the data outputs produced by their data product. A common approach is to make sure that these storage locations, databases, schema’s are properly prefixed with the name of the data product. This approach allows teams to register their data outputs independently, without needing approval from data architects. It also resembles the gold layer in the medallion architecture where new aggregate data is created from other data sources.
 Data product aligned organisation, no involvement from data architects needed due to implicit agreement by convention
Data product aligned organisation, no involvement from data architects needed due to implicit agreement by convention
However, with data spread across various data products, it becomes harder to discover relevant data sources. It will increase your reliance on good data governance practices and tooling i.e. data catalogs. However, this is hard to avoid even with a medallion architecture due to a rapidly increasing number of data products.
This approach works best for business-focused data product teams, where speed, agility and ownership are priorities. Teams can move fast and produce results without needing to rely on data architects to help them organise their data.
2. Source-Aligned Organisation
A source-aligned data organisation is structured around the system from which data is extracted, rather than aligning with specific data products. In most cases, there’s no need to share the raw, unprocessed data (bronze layer) from these source systems. Instead, the focus is on making the cleaned, high-quality data (silver layer) available for sharing. This is where data product teams can guarantee data quality, service-level agreements (SLAs), and formal data contracts.
 Source aligned organisation, requires data architect to approve structure
Source aligned organisation, requires data architect to approve structure
Unlike a data product-aligned organisation, a source-aligned structure is more suited to data engineering focussed teams performing tasks such as ETL (Extract, Transform, Load). These teams are responsible for extracting, cleaning, and preparing data from various source systems, providing reliable data assets for other teams or data products to build on. They possess specialised data engineering expertise, which business-oriented teams often lack.
Because of this close working relationship, it’s usually not an issue for data architects to assist with organising how data needs to be persisted. The source-aligned approach mirrors the structure of the silver layer and offers a more consistent way of organising data across the platform, ensuring high quality standards and governance.
How the Data Product Portal Supports a Self-Service Data Organisation
In this blogpost we discussed the medallion architecture and how it became the de-facto standard for organising data in your data platform. We talked about the need for more self service for organisations that want to scale their data initiatives and why the medallion architecture might not be ideal for that. We also proposed an alternative way of structuring your data that would address these issues for self service data teams.
To help implement a data product thinking approach and guide teams in creating and sharing data products in a self service manner, we created the open-source Data Product Portal. It helps scale self service data initiatives across the organisation without sacrificing control or governance.
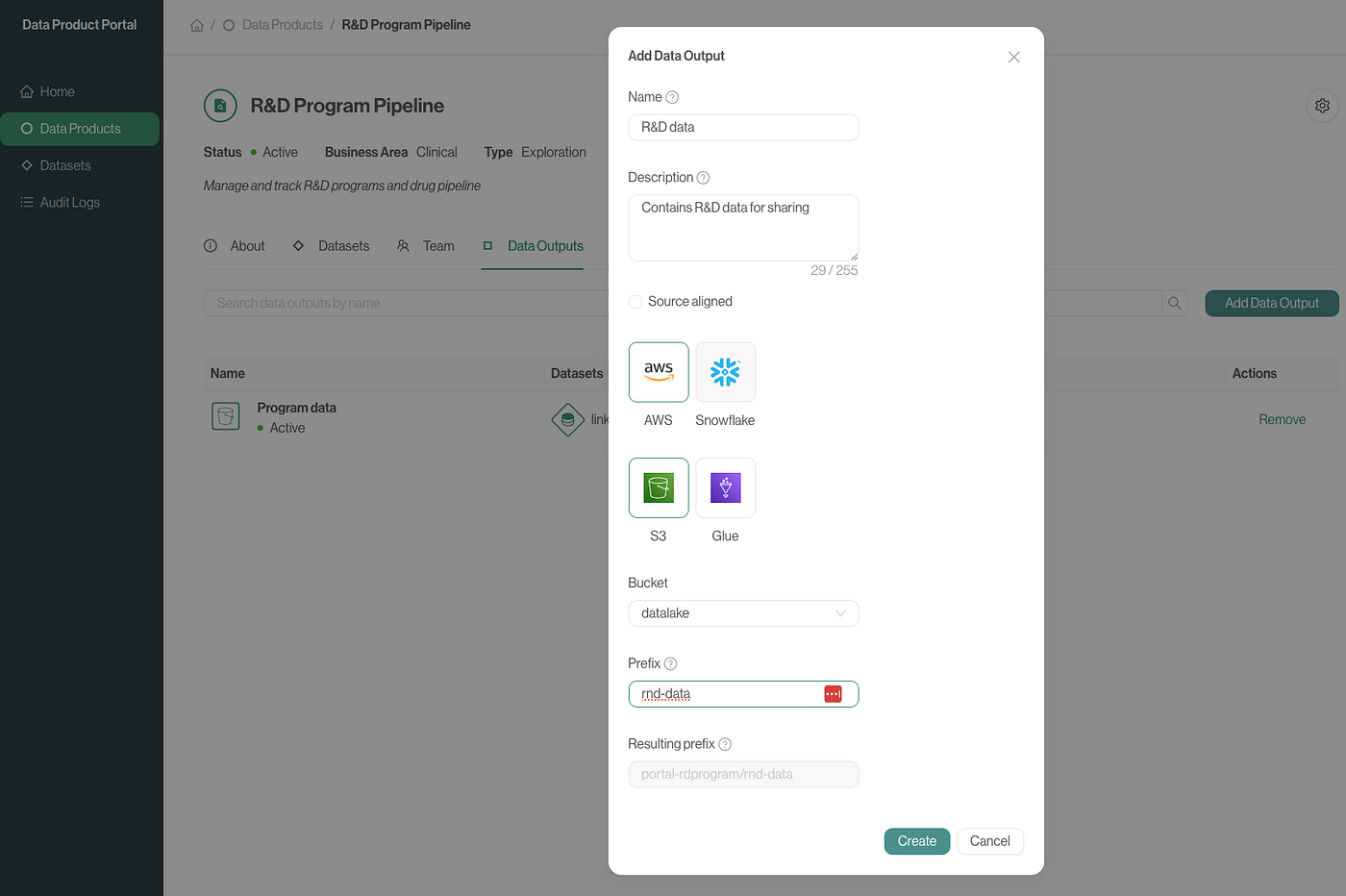 Screen capture of the Data Product Portal while registering a data output for sharing
Screen capture of the Data Product Portal while registering a data output for sharing
In the upcoming release (v0.2.0), the Data Product Portal will support both source-aligned and data product-aligned approaches for registering data outputs for sharing.
- In a data product-aligned model, data outputs are immediately available for use within the scope of that data product.
- In a source-aligned model, data architects must review the outputs before they can be made available for sharing.
Go to Github to get started with Portal and join our community on Slack to follow product updates and join the conversation.




